- تجارت گزینه کالا 101: نمای کلی ، مزایا و استراتژی ها
- سرمایه گذاری قدرت سود مرکب
- امور مالی یاهو
- دوجنشی
- آیا تحلیلگر ایده های تجاری کوتاه مدت ارزشمند است؟
- چرا تنوع و ورود به مطالعه (سریع گرفتن)
- امور مالی یاهو
- نحوه استفاده از نرم افزار Trader Dynamic برای تنظیم تنظیمات زمان و قیمت Fibonacci
- خودآموزی آنلاین
- تعادل حداکثر

آخرین مطالب
امکانات وب


عملکرد PIVOT_TABL PANDAS شبیه به صفحه گسترده است و باعث می شود گروه بندی ، خلاصه و تجزیه و تحلیل داده های شما آسانتر شود. در اینجا نحوه ایجاد خودتان آورده شده است.

نوشته شده توسط ربکا ویکری منتشر شده در 29 سپتامبر 2022
رهبری علوم داده در EDF
ربکا ویکری یک رهبر علوم داده برای شرکت انرژی EDF است که در Python ، Leaing Machine ، AI و برنامه نویسی تخصص دارد. ویکری از سال 2007 در علوم داده کار کرده است. او پیش از این به عنوان دانشمند داده برای موارد اضافی تعطیلات کار می کرد.

تصویر: Shutterstock / ساخته شده در
کتابخانه Pandas یک بسته محبوب پایتون برای تجزیه و تحلیل داده ها است. هنگامی که در ابتدا با یک مجموعه داده در پاندا کار می کرد ، ساختار دو بعدی خواهد بود ، متشکل از ردیف ها و ستون ها ، که به عنوان یک DataFrame نیز شناخته می شوند. بخش مهمی از تجزیه و تحلیل داده ها فرایند گروه بندی ، جمع بندی ، جمع آوری و محاسبه آمار در مورد این داده ها است. جداول محوری پاندا ابزاری قدرتمند برای انجام این تکنیک های تجزیه و تحلیل با پایتون ارائه می دهد.
جدول محوری Pandas خود را در 4 مرحله ایجاد کنید
- داده هایی را که می خواهید استفاده کنید بارگیری یا وارد کنید.
- در عملکرد Pivot_Table ، DataFrame را که خلاصه می کنید ، به همراه نام های شاخص ها ، ستون ها و مقادیر مشخص کنید.
- نوع محاسبه ای را که می خواهید استفاده کنید ، مانند میانگین مشخص کنید.
- برای ایجاد خلاصه قدرتمندتر از داده ها از چندین فهرست و گروه بندی سطح ستون استفاده کنید.
اگر شما یک کاربر صفحه گسترده هستید ، ممکن است قبلاً با مفهوم جداول محوری آشنا باشید. جداول محوری پاندا به روشی بسیار مشابه با آنهایی که در ابزارهای صفحه گسترده مانند مایکروسافت اکسل یافت می شوند ، کار می کنند. تابع جدول Pivot در یک قاب داده و پارامترهای مربوط به شکل مورد نظر شما می خواهد. سپس داده های خلاصه شده را به صورت جدول محوری جمع می کند.
من با نمونه های کد به ابزار جدول Pandas Pivot یک مقدمه مختصر ارائه می دهم. سپس از یک مجموعه داده به نام "Autos" استفاده می کنم که شامل طیف وسیعی از ویژگی های مربوط به اتومبیل ها ، مانند ساخت ، قیمت ، اسب بخار و مایل در هر گالن است.
می توانید داده ها را از OpenML بارگیری کنید ، یا کد را می توانید مستقیماً با استفاده از API Scikit-Lea همانطور که در زیر آمده است ، به طور مستقیم در کد خود وارد کنید.
واردات pandas به عنوان pd واردات numpy به عنوان np از sklea. datasets واردات fetch_openml x ، y = fetch_openml ("autos" ، نسخه = 1 ، as_frame = true ، retu_x_y = true) data = x data ['target'] = yنحوه ایجاد یک جدول محوری پاندا
یک جدول محوری پانداس دارای سه عنصر اصلی است:
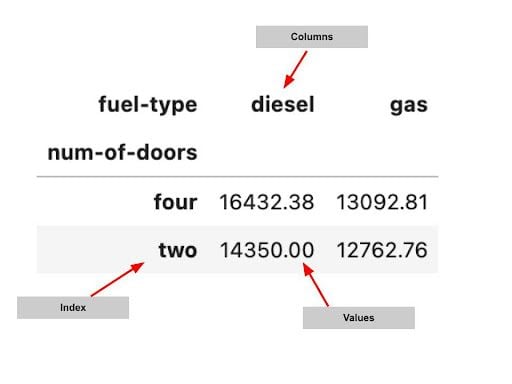
- فهرست: این گروه بندی سطح ردیف را مشخص می کند.
- ستون: این گروه بندی سطح ستون را مشخص می کند.
- مقادیر: این مقادیر عددی است که به دنبال خلاصه آن هستید.
کد مورد استفاده برای ایجاد جدول Pivot را می توان در زیر مشاهده کرد. در عملکرد Pivot_Table ، DataFrame را که خلاصه می کنیم ، مشخص می کنیم و سپس نام ستون برای مقادیر ، فهرست و ستون ها را نشان می دهیم. علاوه بر این ، ما نوع محاسبه ای را که می خواهیم استفاده کنیم مشخص می کنیم. در این حالت ، ما میانگین را محاسبه می کنیم.
pivot = np. round (pd. pivot_table (داده ها ، مقادیر = 'قیمت' ، index = 'num-doors' ، ستون = 'نوع سوخت' ، aggfunc = np. mean) ، 2) محوریجداول محوری می تواند چند سطحی باشد. ما می توانیم از چندین شاخص و گروه بندی سطح ستون برای ایجاد خلاصه های قدرتمندتر از یک مجموعه داده استفاده کنیم.
pivot = np. round (pd. pivot_table (داده ها ، مقادیر = 'قیمت' ، index = ['num-of doors' ، 'body style'] ، ستون ها = ['نوع سوخت' ، 'سیستم سوخت'] ، aggfunc = np. mean ، fill_value = 0) ، 2) محوری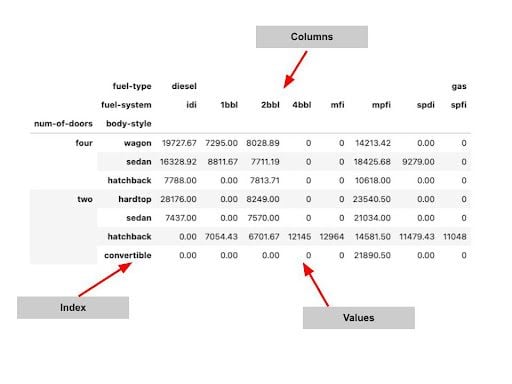
نحوه ترسیم با جدول محوری پاندا
جداول محوری پاندا می تواند در رابطه با قابلیت ترسیم PANDAS برای ایجاد تجسم داده های مفید استفاده شود.
به سادگی اضافه کردن . plot () به انتهای کد جدول محوری شما یک طرح از داده ها ایجاد می کند. به عنوان نمونه ، کد زیر نمودار نوار را ایجاد می کند که میانگین قیمت ماشین را با ساخت و تعداد درها نشان می دهد.
np. round (pd. pivot_table (داده ها ، مقادیر = "قیمت" ، index = ['make'] ، ستون ها = ['num-of-doors'] ، aggfunc = np. mean ، fill_value = 0) ، 2). plot. barh (figsize = (10،7) ، عنوان = "میانگین قیمت ماشین توسط ساخت و تعداد درب ها")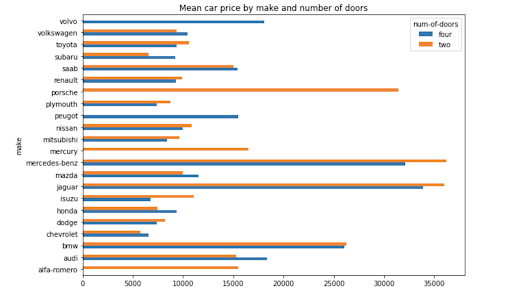
نحوه محاسبه با جدول محوری پاندا
آرگومان Aggfunc در عملکرد جدول محوری می تواند در یک یا چند محاسبات استاندارد انجام شود.
کد زیر میانگین و متوسط قیمت بدنه ماشین و تعداد درها را محاسبه می کند.
np. round (pd. pivot_table (داده ها ، مقادیر = 'قیمت' ، index = ['بدنه به سبک'] ، ستون ها = ['num-of-doors'] ، aggfunc = [np. mean ، np. median] ،fill_value = 0) ، 2)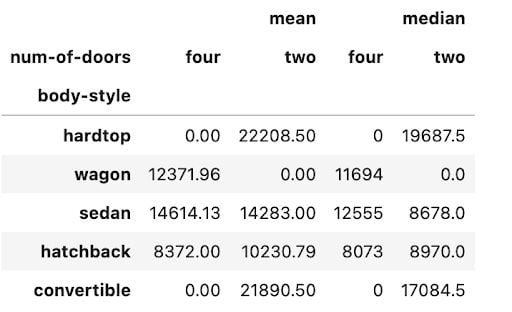
می توانید حاشیه آرگومان را اضافه کنید = درست برای اضافه کردن کل به ستون ها و ردیف ها. همچنین می توانید با استفاده از MARGINS_NAME ، نامی را برای جمع مشخص کنید.
np. round (pd. pivot_table (داده ها ، مقادیر = "قیمت" ، index = ['بدنه سبک'] ، ستون ها = ['num-of-doors'] ، aggfunc = [np. sum] ، fill_value = 0 ،حاشیه = درست ، margins_name = 'total') ، 2)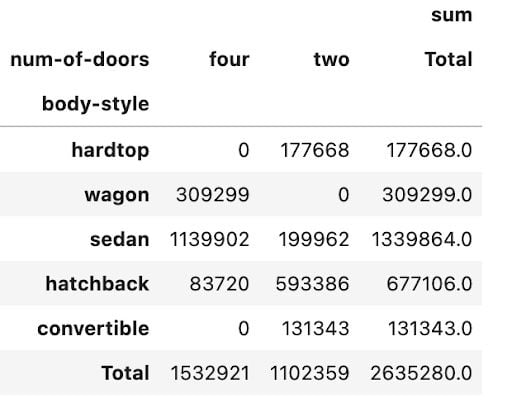
یک آموزش در مورد اصول جداول محوری پاندا.|ویدئو: CodeBasics
چگونه جدول محوری پاندا خود را سبک کنیم
هنگام خلاصه کردن داده ها ، یک ظاهر طراحی شده مهم است. ما می خواهیم اطمینان حاصل کنیم که الگوهای و بینش هایی که جدول Pivot ارائه می دهد ، خواندن و درک آن آسان است. در جداول محوری مورد استفاده در قسمت های اولیه مقاله ، یک ظاهر طراحی بسیار کمی اعمال شده است. در نتیجه ، جداول قابل درک و یا بصری جذاب نیست.
ما می توانیم از روش پانداس دیگری استفاده کنیم که به عنوان روش سبک شناخته می شود تا جداول زیباتر به نظر برسد و از بینش راحت تر شود. کد زیر قالب بندی مناسب و واحدهای اندازه گیری را به هر یک از مقادیر مورد استفاده در این جدول محوری اضافه می کند. اکنون تمایز بین دو ستون و درک آنچه داده ها به شما می گویند بسیار ساده تر است.
pivot = np.round(pd.pivot_table(data, values=['price', 'horsepower'], index=['make'], aggfunc=np.mean, fill_value=0),2) pivot.style.format(', 'horsepower':'hp'>)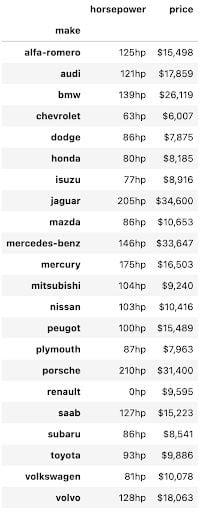
ما می توانیم قالبهای مختلف را با استفاده از استایلر ترکیب کنیم و از سبک های داخلی پاندا استفاده کنیم تا داده ها را به شکلی خلاصه کنیم که فوراً بینش ها را بیرون می کشد. در جدول کد و محوری که در زیر نشان داده شده است ، ما سفارش ساخت خودرو را از طریق قیمت از ارزش بالا به پایین ، قالب بندی مناسب به اعداد اضافه کرده ایم و یک نمودار نوار را اضافه کرده است که مقادیر را در هر دو ستون پوشانده است. این امر نتیجه گیری از جدول را آسان تر می کند ، مانند این که ماشین گران ترین است و اینکه چگونه اسب بخار با قیمت هر ماشین ارتباط دارد.
pivot = np.round(pd.pivot_table(data, values=['price', 'horsepower'], index=['make'], aggfunc=np.mean, fill_value=0),2) pivot = pivot.reindex(pivot['price'].sort_values(ascending=False).index).nlargest(10, 'price') pivot.style.format(', 'horsepower':'hp'>) . bar (رنگ = '#d65f5f')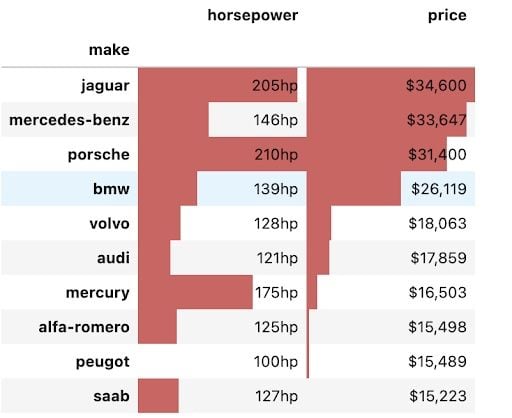
مزایای جداول محوری پاندا
جداول محوری از اوایل دهه 90 با ثبت اختراع مایکروسافت در نسخه معروف اکسل معروف به "pivottable" در سال 1994 استفاده شده است. آنها هنوز هم امروزه مورد استفاده قرار می گیرند زیرا آنها ابزاری قدرتمند برای تجزیه و تحلیل داده ها هستند. جدول Pandas Pivot این ابزار را از صفحه گسترده و به دست کاربران پایتون بیرون می آورد.
این راهنما مقدمه ای کوتاه در مورد استفاده از ابزار جدول Pivot در پاندا ارائه داد. این به معنای این است که یک آموزش سریع را برای بلند شدن و اجرای این ابزار به یک مبتدی اختصاص دهد اما پیشنهاد می کنم در اسناد پاندا حفر کنید ، که راهنمای عمیق تری برای این عملکرد ارائه می دهد.
استراتژی برای تجارت گزینه های...
ما را در سایت استراتژی برای تجارت گزینه های دنبال می کنید
برچسب :
نویسنده : فریبا کامران
بازدید : 26
