- تجارت گزینه کالا 101: نمای کلی ، مزایا و استراتژی ها
- سرمایه گذاری قدرت سود مرکب
- امور مالی یاهو
- دوجنشی
- آیا تحلیلگر ایده های تجاری کوتاه مدت ارزشمند است؟
- چرا تنوع و ورود به مطالعه (سریع گرفتن)
- امور مالی یاهو
- نحوه استفاده از نرم افزار Trader Dynamic برای تنظیم تنظیمات زمان و قیمت Fibonacci
- خودآموزی آنلاین
- تعادل حداکثر

آخرین مطالب
امکانات وب


در این مقاله یک روش از پایین به بالا برای تشخیص صفات سبکی در نحو متون ادبی ارائه و توصیف شده است. استخراج الگوهای نحوی کورکورانه توسط یک الگوریتم معدن الگوی پی در پی انجام می شود ، در حالی که شناسایی ویژگی های قابل توجه و جالب در مرحله بعدی با استفاده از تجزیه و تحلیل مکاتبات و با استفاده از الگوهای رتبه بندی با کمک انجام می شود.
سبک شناسی محاسباتی
سبک شناسی محاسباتی نوعی تجزیه و تحلیل ادبی به کمک رایانه است ، که هدف آن استخراج صفات قابل توجه سبکی است که یک اثر ادبی ، یک نویسنده ، یک ژانر ، یک دوره را نشان می دهد ... سبک محاسباتی شباهت هایی را با انتساب نویسندگی رایانه ای به اشتراک می گذارد. در واقع روشهای استایلومتری به منظور شناسایی محتمل ترین نویسنده متنی از انتساب ناشناخته شروع به توسعه شده اند (برای بحث به [کریگ 2004] مراجعه کنید).
اصطلاح استایلومتری ([Grzybek 2014] برای تاریخچه مفهوم) می تواند و به عنوان یک ابرنواختر برای هر دو رشته مورد استفاده قرار گرفته است. مشترکات در روش نهفته است. با انتخاب مجموعه ای از متون ، برخی از خصوصیات قابل اندازه گیری مشخص می شوند و متون برای چنین خصوصیاتی یا ویژگی ها استخراج می شوند. ویژگی ها می توانند بسیار متنوع باشند.
ویژگی های بسیار اساسی صفاتی مانند تعداد جملات در یک متن ، تعداد کلمات در یک متن ، تعداد متوسط کلمات در یک جمله ، متوسط طول کلمه ، فرکانس نگارشی است. ویژگی های دیگر به درستی زبانی ، مربوط به اندازه واژگان یک متن (غنای واژگانی) ، فرکانس کلمات عملکرد ، فرکانس برچسب های گفتار (POS) یا GRAMS POS [1] ، پیچیدگی نحوی [2] و غیره است. بدیهی است که برخی از ویژگی های سطح بالاتر برای انجام حاشیه نویسی به شمارش دستی یا یک ابزار قابل اعتماد NLP نیاز دارند.
پس از انتخاب و شمارش ویژگی ها ، هر متن را می توان به عنوان یک بردار مشاهده کرد که برای هر ویژگی شمارش چنین ویژگی در خود متن را نشان می دهد. متون مختلفی که باید مقایسه شوند ، ماتریسی مانند نمونه ای که در جدول 1 نشان داده شده است ، تشکیل می دهند. شمارش می تواند به صورت مطلق یا نسبی باشد. عادی سازی هنگامی توصیه می شود که اندازه متون متفاوت باشد. با این وجود باید در نظر گرفت که متون کوچکتر به طور کلی دارای تنوع داخلی بالاتری هستند. بنابراین توصیه می شود متون با اندازه های خیلی متفاوت را با یکدیگر مقایسه نکنید و گاهی اوقات آزمایش ها بر روی نمونه های انتخاب شده با اندازه مساوی انجام می شود.
| ویژگی 1 | ویژگی 2 | ویژگی 3 | |
| متن 1 | 30 | 15 | 6 |
| متن 2 | 403 | 30 | 515 |
| متن 3 | 305 | 149 | 58 |
میز 1. مثالی از یک ماتریس حاوی تعداد سه ویژگی قابل شمارش ممکن.
سپس می توان از چندین روش برای اندازه گیری و مقایسه متون بر اساس فراوانی ویژگی ها استفاده کرد. آنها معمولاً بر اندازه گیری فاصله برداری تکیه می کنند که به فرد اجازه می دهد تشخیص دهد که آیا دو متن رفتار یکسانی را با توجه به ویژگی های انتخاب شده نشان می دهند یا خیر. به عنوان مثال در جدول 1 واضح است که متن های 1 و 3 علیرغم تفاوت در مقیاس، توزیع های مشابهی را نشان می دهند، زیرا آنها تقریباً نسبت ویژگی های 1، 2 و 3 یکسان دارند، در حالی که متن 3 رفتار کاملاً متفاوتی را نشان می دهد، با مقدار بالاتر. برای ویژگی 3 نسبت به ویژگی 1 و 2 حساب کنید.
شباهت روش ها علی رغم هدف سبک شناسی محاسباتی، عمیقاً با روش اسناد نویسندگی متفاوت است. در واقع، هدف روش های انتساب شناسایی ویژگی های ناخودآگاه در اثر یک نویسنده است که او را از دست می دهد و به همین دلیل معمولاً به عنوان اثر انگشت تعریف می شود. ویژگی های اساسی ذکر شده در بالا (مانند طول کلمه یا جمله)، همراه با توزیع کلمه تابع، تا کنون ثابت کرده اند که اثر انگشت بسیار کارآمد هستند. ممکن است چنین ویژگی هایی در یک نویسنده تا حدودی مستقل از نوع متنی که او می نویسد، وجود داشته باشد، حتی به غیر از تولید ادبی به معنای دقیق (بنابراین، می توان آنها را در نامه های شخصی او جستجو کرد).
از سوی دیگر سبک ادبی چیزی است که نویسنده به شیوه ای آگاهانه تر به آن تسلط دارد. ممکن است آثار مختلف یک نویسنده ویژگی های سبکی متفاوتی را نشان دهد، اگرچه در همه آثار او آثار دیگری نیز دیده می شود. به طور کلی، می توان فرض کرد که ویژگی های پیچیده تر زبانی به شیوه ای آگاهانه تر و کنترل شده تر استفاده می شوند و بنابراین زمانی که برخی از آنها به شدت در نویسنده نسبت به دیگران بیش از حد مورد استفاده قرار می گیرند یا کمتر مورد استفاده قرار می گیرند، این ممکن است به عنوان امکان پذیرفته شود. ویژگی سبکی
علاوه بر این، انتساب نویسندگی را می توان به وضوح به عنوان یک مشکل طبقه بندی (که محتمل ترین نویسنده متن A با توجه به دسته ای از نامزدها است) در نظر گرفت و در واقع به این ترتیب نه تنها در ادبیات بلکه در زمینه های پزشکی قانونی نیز اعمال می شود. سبک محاسباتی یک مسئله باز است [کریگ 2004] که شامل شناسایی ویژگی هایی است که متمایزترین مجموعه ای از متون با توجه به متون دیگر هستند. بنابراین از دیدگاه محاسباتی، روش های سبک محاسباتی به عنوان الگوریتم هایی چارچوب بندی می شوند که ویژگی های زبانی را در یک متن معین بر اساس معیارهای جذابیت رتبه بندی می کنند.
واضح است که ارزیابی چنین معیارهایی از نظر معیارهای دقتی که معمولاً در بازیابی اطلاعات استفاده می شود دشوارتر است. در حال حاضر بحثی در جریان است که آیا روش های سبک محاسباتی باید راهی برای تغییر اساسی روش شناسی نقد ادبی و «علمی تر کردن» آن باشد. کتاب تاثیرگذار رمزی، ماشین های خواندن. نسبت به یک انتقاد الگوریتمی [رامسی 2011] به ما می گوید که ممکن است اینطور باشد اما لازم نیست.
روش ارائه شده در این مقاله تفاوت های جالبی را در استفاده از ساختارهای نحوی از مجموعه متون مشخصی استخراج و رتبه بندی می کند و با مقایسه چهار رمان از چهار نویسنده مختلف نشان داده خواهد شد. بنابراین، این یک الگوریتم اکتشافی - مبتنی بر مجموعه ای از ابزارهای محاسباتی آزادانه در دسترس است - که هدف آن ارائه کمکی به محققان ادبی بدون تغییر اساسی روش عادی تحلیل آنهاست. به همین دلیل نباید برای کشف حقایق کاملاً جدید در مورد سبک ادبی، بلکه برای اثبات (یا رد) حقایق شناخته شده به کار رود[3]. به طور خاص، تجزیه و تحلیل کیفی نتایج که در بخش دوم این مقاله ارائه شده است، یک بستر آزمایشی ارزیابی و همچنین کمکی برای دانشمندان کامپیوتر و متخصصان NLP برای تنظیم دقیق روش هایشان است.
این یک سناریوی غیر معمول در تحقیقات سبک شناسی محاسباتی امروزی نیست. می توان آن را با مراحل اولیه زبان شناسی تاریخی مقایسه کرد، زمانی که محققان روش تطبیقی بازسازی ژنتیکی خود را بر روی زبان های رومی ایجاد کردند، که در واقع مقدمه (لاتین) برای آن موجود بود. تنها امکان تأیید مستقل روش های آن ها بر روی یک منبع تأیید شده می تواند صحت روش های مقایسه ای را ثابت کند و به محققان اجازه می دهد تا متعاقباً سایر زبان های اولیه را که هیچ گواهی برای آنها وجود نداشت (آلمانی، هندواروپایی) بازسازی کنند.
علی رغم این هشدار، ما معتقدیم که روش شناسی ما، در کنار سایر رویکردهای مشابه، می تواند برای متخصصانی که می توانند تأیید حقایق شناخته شده را بیابند و در نتیجه ادعاهای خود را با داده های بیشتری اثبات کنند، مفید باشد. با ارزش افزوده ای که چنین الگوریتم هایی می توانند به راحتی مقادیر زیادی از متن را پردازش کنند، و بنابراین می توانند در آن بخش از ادبیات که فرانکو مورتی [مورتی 2005] آن را آرشیو می نامد، به ویژه برای آثاری که پایین تر آن ها هستند، اعمال شوند. اعتبار ادبی و تعداد زیاد روش های محاسباتی را جذاب تر می کند.
سبک شناسی محاسباتی
آثار بررسی تفاوتهای واژگانی بین نویسندگان با استفاده از تکنیک های استیلومتری در ادبیات رایج است. به طور کلی ، مطالعات عناصر واژگانی فردی را شمارش و مقایسه می کند (نمونه هایی از شکسپیر و سایر نمایشنامه نویسان را در [کریگ 2009] ، در میان بسیاری دیگر) یا الگوهای واژگانی (یا بسته بندی ها ، مانند [Mahlberg 2013]) مشاهده کنید. تکنیک های مشابه برای مطالعه ژانرها و روندهای ادبی در یک دیدگاه تاریخی ، در آثاری که اغلب تحت عنوان کلمات خواندن دور [Moretti 2005] یا ماکروالیز [Jockers 2013] می روند ، اعمال می شود. سرانجام ، نمونه برداری از متداول ترین کلمات در مجموعه ای از متون بر اساس برخی از گسترده ترین تکنیک های مربوط به نویسندگی ، مانند دلتای Burrows [Burrows 2002] و برنامه های بعدی آن [Rybicki 2011] است.
بعضی اوقات مجموعه ها با ابزارهای سازگار [Mahlberg 2013] استخراج و مورد تجزیه و تحلیل قرار می گیرند و سپس با یک Corpus Norm مقایسه می شوند (این رویکردی است که معمولاً در سنت سبک شناسی Corpus دنبال می شود زیرا کارهای اصلی Geoffrey Leech). در موارد دیگر از روشهای کاهش ابعاد برای نشان دادن گرافیکی تفاوتهای بین متون با طرح ریزی در یک فضای دو بعدی فاصله بین بردارهای نمایانگر متون استفاده می شود. مقیاس بندی چند بعدی (MDS) ، تجزیه و تحلیل مؤلفه اصلی (PCA) و تجزیه و تحلیل مکاتبات (CA) اغلب برای این منظور استفاده می شوند [Burrows 2012] ، و در چندین ابزار برای تجزیه و تحلیل سبک اجرا می شوند [4]. چنین روش هایی جالب است زیرا به محقق اجازه می دهد با مشاهده خوشه هایی که در نمودار ظاهر می شوند ، فرضیات پیشینی را در مورد شباهت/فاصله متون مختلف تأیید کنند. علاوه بر این ، برخی از این تکنیک ها (PCA و CA) امکان نمایش بصری را در نمودار ویژگی هایی که بیشتر با یک متن در ارتباط هستند نسبت به سایر موارد فراهم می کند.
هنگام کار با تعداد کمی از ویژگی های از پیش انتخاب شده ، یک تکنیک متداول که به کاربر در مورد فرایند تصمیم گیری که الگوریتم مورد استفاده برای تولید تجسم استفاده می کند ، به اصطلاح دو نقشه است (برای مثال شکل 1 را ببینید).
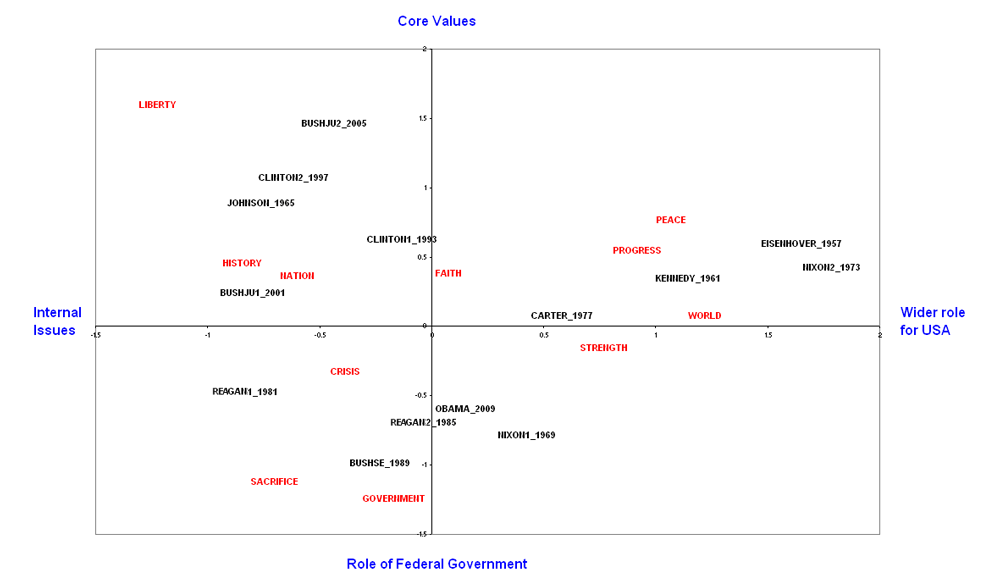
شکل 1.
کاوش در آدرسهای افتتاحیه ریاست جمهوری ایالات متحده. قطعه ای از هوس در مورد متن و متن. نمونه ای از مستندات نرم افزار TLAB [5]
همانطور که از طرح مشاهده می کنید ، متون در فضای دو بعدی به همراه ویژگی های انتخاب شده نمایش داده می شوند. این تجسم ویژگی های موجود در فضای نزدیک متونی را که با آنها بیشتر در ارتباط هستند قرار می دهد. این بدان معنی است که محقق می تواند به راحتی تشخیص دهد که کدام ویژگی ها مسئولیت تفاوت بین متون را بر عهده دارند. همچنین ، موقعیت نسبی ویژگی ها با توجه به یکدیگر نشان دهنده معنای احتمالی است که نمایندگی در طول دو محور طول می کشد. برچسب های موجود در رنگ آبی در خارج از طرح در شکل 1 ، تفسیری است که یک انسان ممکن است از توزیع دو بعدی از ویژگی ها ارائه دهد.
چنین روشهای تجسم نقش بسیار مهمی دارند که به محقق اجازه می دهد نه تنها طبقه بندی پیشینی داده شده را تأیید یا دور بیندازد ، بلکه توضیح می دهد که دلیل این امر وجود دارد. به این معنا ، در کنار مطالعات مبتنی بر فرضیه ، آنها همچنین می توانند ابزاری برای بررسی و تجزیه و تحلیل ارائه دهند که بیشتر مطابق با شیوه های مشترک در انتقادات ادبی باشد.
واضح است که از چنین تکنیک هایی می توان نه تنها برای مطالعه واژگان نویسندگان ، بلکه برای تلاش و تشخیص تفاوت های نحوی در سبک استفاده کرد. تجزیه قابل اعتماد همیشه در دسترس نیست ، و ممکن است حتی برای انگلیسی ها نیز به خوبی در متن های ادبی کار کند. با این وجود ، الگوهای نحوی به شکل Grams یا ساخت و سازها به راحتی قابل دستیابی است ، زیرا امروزه برچسب گذاری POS در بسیاری از زبان ها و دامنه ها در دسترس است.
- یا یک رویکرد از بالا به پایین برای انتخاب ویژگی انتخاب می شود و بدین ترتیب مجموعه ای محدود از ساختارهای نحوی را پیش بینی می کند (برای مثال ، در میان دیگران ، [Dell'orletta 2011]).
- یا الگوریتم های استخراج الگوی پایین به بالا استفاده می شود ، که امکان ایجاد مجموعه ای از ویژگی های باز را فراهم می کند.
این دو سناریو از تمایز معرفی شده توسط [Quiniou 2012] بین رویکردهای پارادایم ، تمرکز بر شمارش دسته ها ، و رویکردهای نحوی که هدف از خصوصیات ترکیبی زبان را نشان می دهد ، آینه می شود.
بدیهی است که گزینه دوم بیشتر مطابق با ایده یک ابزار اکتشافی است و به ما امید می دهد که بتوانیم از چنین تکنیک هایی در آینده استفاده کنیم تا حقایق جدیدی را در مورد متون ادبی کشف کنیم. با این وجود ، الگوریتم های استخراج الگوی (مانند معدن الگوی پی در پی ، که ما در بند بعدی ارائه خواهیم داد) شناخته شده اند که تعداد عظیمی از الگوهای و در نتیجه بردارهای بزرگ ، حتی برای بخش های کوچک متن تولید می شوند. بنابراین دو قطعه ، که برای اکتشاف بسیار مفید هستند ، به دلیل پیش بینی هزاران ویژگی قابل خواندن نیستند. در بخش های بعدی این مقاله یک روش رتبه بندی ویژگی ارائه شده است که هدف آن غلبه بر چنین موانعی است ، بنابراین به محققان این امکان را می دهد تا یک روش انتخاب ویژگی از پایین به بالا و تجسم اکتشافی از نتایج را ترکیب کنند.
روش شناسی
- حاشیه نویسی داده ها
- استخراج الگوی
- تصفیه الگوی
- تجزیه و تحلیل مکاتبات و تجسم
- استخراج الگوی
داده ها ابتدا به جملات تقسیم می شوند ، سپس دسته های نحوی با استفاده از یک ابزار آزادانه در دسترس ، Treetagger [Schmid 1994] ، [Schmid 1995] حاشیه نویسی می شوند.[استین 2003] برای برچسب فرانسوی که در اینجا استفاده می شود). مثال 1 نشان می دهد که چگونه یک جمله فرانسوی حاشیه نویسی می شود:
جدول Le Livre est sur la. DET: ART - NOM - VER: PRP - PRP - DET: ART - NOM - ارسال شده مثال 1.
- - توالی توالی های برچسب POS کامل یا ساده (DET: ART - NOM - VER: PRES VS DET - NOM - VER)
- - با یا بدون درج عناصر واژگانی (Le - Nom - ver: Pres در مقابل Det: Art - Nom - EST)
- - با یا بدون شکاف (det: art - nom - ver: pres vs. det: art - [*] - est)
- - از هر طول معین (به طور معمول حداکثر 5 موقعیت از جمله شکاف)
- الگوی 1: det - nom - ver - prp - det = f. 50
- الگوی 2: det - nom - ver - prp = f. 50
این روش استخراج بر روی چندین شرکت مانند نمایشنامه های تئاتری ، شعرها و رمان ها آزمایش شده است. با توجه به اندازه شرکت ها و تنظیمات ، این روش استخراج می تواند تا 10،000 الگوی تولید کند که در سطح جهان می تواند به عنوان توصیف نحوی متن دیده شود. بنابراین این روش برای دور زدن مرحله انتخاب ویژگی است. محقق نیازی به تهیه لیستی از توالی های نحوی احتمالی ندارد که ممکن است یک متن را از دیگران متمایز کند. الگوهای از پایین به بالا و کورکورانه استخراج می شوند. بدیهی است که مقدار زیادی از چنین الگوهای برای تمایز سبک ناچیز خواهد بود زیرا احتمالاً در تمام متون فرکانس یکسانی دارند.
- بردارهای الگوی از تمام متون تحت تجزیه و تحلیل به یک ماتریس بزرگ وارد می شوند
- الگوهای موجود در یک متن به طور پیش فرض صفر اختصاص داده می شوند ، (هموار سازی نیز امکان پذیر است)
- ماتریس ممکن است عادی شود یا نباشد ، فرکانس های مطلق را به موارد نسبی تبدیل می کند.
- تجزیه و تحلیل مکاتبات با استفاده از ابزار Factominer برای R [Husson 2011] انجام می شود
- مشارکت برای هر الگوی استخراج می شود
- فیلتر الگوی انجام می شود
- توطئه ها و جداول نتیجه چاپ می شوند
تجزیه و تحلیل مکاتبات (CA) یک تکنیک کاهش ابعادی است که توسط ژان پل بنزری ([بنزری 1977] ، [Greenacre 2007]) تهیه شده است که به خوبی شناخته شده است و اغلب در علوم انسانی دیجیتال و تجزیه و تحلیل متنی مورد استفاده قرار می گیرد [Lebart 1998]. مزیت اصلی استفاده از CA با توجه به ، مثلاً PCA ، و در استفاده از یک ابزار پیشرفته مانند Factominer برای انجام آن به جای برخی از GUI های استوانه ای که معمولاً استفاده می شود ، این است که نتایج کامل تجزیه و تحلیل در یک ساختار داده سری موجود استبشردو جدول حاوی مختصات برای طرح ریزی متون و الگوهای موجود در طرح هستند. اینها امکان چاپ انتخابی زیر مجموعه الگوهای موجود در طرح را فراهم می کند. علاوه بر این ، نزدیکی یک الگوی با هر یک از متون را می توان به راحتی با فاصله اقلیدسی محاسبه کرد ، بنابراین امکان شناسایی خودکار الگوهای به شدت با یک متن نسبت به سایرین فراهم می شود.
سوم مهمترین جدول نتیجه برای روش شناسی ما است و شامل سهم هر الگوی در دو محور است. سهم به عنوان سهم واقعی آن الگوی در جابجایی کلی موقعیت متون در طرح حاصل تعریف می شود. اگر یک الگوی به شدت در متن با توجه به دیگران نمایان شود ، در جابجایی متن در فضای دو بعدی نقش زیادی خواهد داشت. بنابراین ، میانگین سهم در دو محور این الگوی بالاتر از یکی از الگوهای دیگر است که کم و بیش فرکانس های یکسان در همه متن ها دارند. پس از آن ، از مشارکت می توان به عنوان یک اقدام جالب برای رتبه بندی الگوهای استفاده کرد.
سرانجام ابزار استخراج EREMOS همچنین به یک روش بازیابی نمونه مجهز است. این به محققان این امکان را می دهد تا تمام موارد موجود در متن مربوط به هر الگوی معین را ببینند. این ویژگی دوم نیز بسیار مهم است زیرا متخصصان می توانند شواهد را در متون تأیید کنند و الگوهای شناسایی شده به طور خودکار را به ساختارهای زبانی واقعی ترسیم کنند که چنین الگویی در واقع آینه دار هستند.
ما با یک مثال خواهیم دید که چگونه این کار به طور عملی کار می کند. بحث فعلی در نظر گرفته نشده است که یک تجزیه و تحلیل انتقادی کامل از متون انتخاب شده باشد ، بلکه هدف این است که فقط نشان دهد که چه مواردی ممکن است کارشناسان از داده ها استفاده کنند.
یک آزمایش: چهار رمان کلاسیک فرانسوی
- ویکتور هوگو ، نوتردام د پاریس
- Honoré de Balzac ، Grandet Eugenie
- گوستاو فلوبرت ، مادام بواری
- Emile Zola ، Le Ventre de Paris.
- از 3 تا 5 موقعیت
- از برچسب های POS ساده
- بدون شکاف
- بدون عناصر واژگانی.
- patte_1 [8]: det - nom - ver
- Patte_2: Ver - PRP - Det - NOM
- الگوی_ 3: det - nom - ver - prp - det

ما را در سایت استراتژی برای تجارت گزینه های دنبال می کنید
برچسب :
نویسنده : فریبا کامران
بازدید : 25
