- تجارت گزینه کالا 101: نمای کلی ، مزایا و استراتژی ها
- سرمایه گذاری قدرت سود مرکب
- امور مالی یاهو
- دوجنشی
- آیا تحلیلگر ایده های تجاری کوتاه مدت ارزشمند است؟
- چرا تنوع و ورود به مطالعه (سریع گرفتن)
- امور مالی یاهو
- نحوه استفاده از نرم افزار Trader Dynamic برای تنظیم تنظیمات زمان و قیمت Fibonacci
- خودآموزی آنلاین
- تعادل حداکثر

آخرین مطالب
امکانات وب


من معتقدم که توانایی خواندن یک جدول رگرسیون یک کار مهم برای دانشجویان کارشناسی ارشد در علوم سیاسی است. اغلب اوقات ، تجزیه و تحلیل واقعی در یک مقاله اختصاص داده شده به یک صفحه تبدیل کننده برای دانش آموز تبدیل می شود که می گوید بدون اینکه واقعاً آن را بخواند ، آن را درک کند ، و آن را ارزیابی کند ، و آن را ارزیابی می کند. این می تواند در زمینه من خطرناک باشد. بعضی اوقات ، جداول رگرسیون ، ظاهراً به عنوان اثبات قطعی به نفع برخی استدلال ها ، می تواند گمراه کننده باشد. اثبات آنقدر قانع کننده نیست که به نظر می رسد. دانشجویی که قادر به خواندن و ارزیابی جدول رگرسیون است ، بهتر می تواند ادعاهای تجربی رقیب را در مورد موضوعات مهم در علوم سیاسی ارزیابی کند. من همچنین معتقدم که یادگیری این ابزار پس از فارغ التحصیلی ، دانش آموز را به چشم انداز بهتری در بازار کار تبدیل می کند و ممکن است دانش آموز را به یک شهروند دموکراتیک بهتر در دنیایی تبدیل کند که به سمت کمیت حرکت می کند.
با این حال ، دانش آموزان می توانند بدون دستیابی به این توانایی از سال اول به سالمندان مراجعه کنند. من هرگز این مطالب را یاد نگرفتم که من در مقطع کارشناسی ارشد بودم که سالها پیش اعطا می شد. کلاسهای روشهای کمی اغلب کلاسهای ویژه در علوم سیاسی هستند. فقط تعداد کمی از خودشان انتخاب شده برای دستیابی به این ابزار هرچند دانش گسترده تری در بین دانشجویان علوم سیاسی سودمند خواهد بود.
آنچه در زیر می آید ، راهنمایی برای دانشجویان مقطع کارشناسی ارشد در خواندن جدول رگرسیون است. جایی که فقط یک پست وبلاگ است ، این راهنما "سریع و کثیف" خواهد بود و بحث جامع تری در مورد مفاهیم و نظریه های اصلی را به یک کلاس روش های کمی (که شما نیز می توانید با من ببرید!) خواهد گذاشت. مخاطبان من برای این پست شامل دانشجویان من در دوره های موضوعی عمومی تر است که با این وجود تأکید بر تحقیقات کمی است.
مرحله اول: داده ها را بشناسید
برخی از بزرگترین خطاهای تفسیر نادرست از یک جدول رگرسیون ناشی از عدم دانستن آنچه در حال آزمایش است و نویسنده در تلاش است حتی با یک رگرسیون خطی یا لجستیک اساسی انجام دهد. به طور خلاصه ، هیچ میانبر برای مبتدیان در خواندن طرح تحقیق یک مقاله نیز وجود ندارد. دانستن اینکه متغیرها چیست و چگونه آنها توزیع می شوند ، پیامدهایی در مورد نحوه خواندن جدول رگرسیون در بخش نتایج دارند.
برای نشان دادن این مرحله ، من می خواهم با یک مجموعه داده ساده در R. تماس بگیرم. این مجموعه داده های رأی است که با بسته Zelig استاندارد است. 1 من با بحث در مورد مجموعه داده ها و هدف آن شروع می کنم.
بیایید بگوییم که می خواهیم بدانیم چه چیزی توضیح می دهد که آیا کسی یک رای دهنده ثبت نام شده است یا خیر. این هدف ماست و این پدیده ای است که می خواهیم توضیح دهیم. ما معتقدیم که می توانیم با مراجعه به سن شخص ، سطح درآمد ، تحصیلات و جنسیت ، چه کسی رای دهنده ثبت شده باشد. این همه چیزهای اساسی جامعه شناختی است ، اما ما معتقدیم که آنها به ما اهرم می کنند تا در چه کسی یک رای دهنده ثبت شده ثبت شده باشد.
ما بدیهی است که نمی توانیم در مورد 300 میلیون یا آمریکایی در این کشور اطلاعاتی کسب کنیم. با این حال ، ما می توانیم نمونه تصادفی از آن جمعیت را بدست آوریم و از نمونه به جمعیت استنباط کنیم. اگر نمونه ما واقعاً تصادفی باشد ، آمار نمونه ما (به علاوه/منهای خطای نمونه برداری) بهترین برآورد ما از پارامتر جمعیت مورد علاقه است. این روند آمار استنباطی است (یعنی استنباط از نمونه ای از جمعیت به خود جمعیت).
ما در نوامبر 2000 از 2000 بررسی جمعیت فعلی داده ها از 1500 آمریکایی به دست آوردیم. 500 پاسخ دهنده از آرکانزاس هستند و 1000 پاسخ دهنده از کارولینای جنوبی هستند. متغیر وابسته (یعنی تنوع آن را می خواهیم توضیح دهیم) رأی خوانده می شود. این دو مقدار را به خود اختصاص می دهد (0 = یک رای دهنده ثبت شده ، 1 = رای دهنده ثبت شده). سن ، به طور شهودی ، سن پاسخ دهنده در سالهاست. جوانترین 18 سال و پیرترین 85 است. درآمد یک متغیر سفارش داده شده بین 4 تا 17 است. در این متغیر ، 4 نفر شخصی را ضبط می کند که سالانه کمتر از 5000 دلار درآمد دارد. 17 کد شخصی که سالانه بیش از 75000 دلار درآمد دارد. آموزش و پرورش ارزش های 1 را به خود اختصاص می دهد (دبیرستان را کامل نکرد) ، 2 ، 3 و 4 (بیش از یک تحصیلات دانشگاهی). زن متغیر باینری دیگری است که در آن 0 = مردان و 1 = زن. خلاصه ای از داده ها به شرح زیر است.
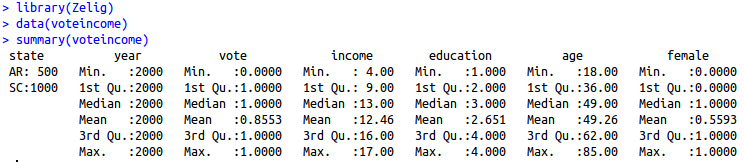
A summary of the voteincome data set in Zelig.>
این خلاصه تصویری برای هدف این پست وبلاگ است. هنگامی که دانش آموز تکلیف مقاله خود را می خواند ، کار دانش آموز باید شامل خواندن طرح تحقیق باشد تا یک حس ، هرچند کلی ، از آنچه نویسنده در تلاش است انجام دهد و داده ها به نظر می رسد ، باشد.
مرحله دوم: درک جدول رگرسیون چه می گوید
در این بخش بحث جامع تری در مورد منطق رگرسیون و تناسب یک رگرسیون خود حذف خواهد شد. داستان کوتاه ، رگرسیون ابزاری برای درک پدیده مورد علاقه به عنوان یک عملکرد خطی از برخی دیگر از متغیرهای پیش بینی کننده است. فرمول رگرسیون به خودی خود شباهت محکمی به معادله شیب-غیرفعال (Y = MX + B) دارد که دانش آموزان باید از دبیرستان به خاطر بسپارند.
در تصویر ما ، ما معتقدیم که می توانیم الگوبرداری کنیم که آیا کسی به عنوان یک معادله خطی از سن ، جنسیت ، سطح تحصیلات و درآمد شخص ثبت شده است. به طور خلاصه: رای = سن + زن + تحصیلات + درآمد در مجموعه داده های ما. وقتی این کار را انجام می دهیم ، خروجی می گیریم که به نظر می رسد.
یک نتیجه صیقلی شبیه به این جدول است ، اگرچه این ارائه خاص به بسته Stargazer در R. نیاز دارد
توضیح رای دهندگان ثبت شده در سال 2000 (آرکانزاس ، کارولینای جنوبی)
| متغیر وابسته: | |
| آیا مخاطب رای دهنده است؟ | |
| سن | 0. 016 *** |
| (0. 004) | |
| زن | 0. 310 ** |
| (0. 151) | |
| تحصیلات | 0. 225 ** |
| (0. 090) | |
| درآمد | 0. 094 *** |
| (0. 022) | |
| ثابت | -0. 878 ** |
| (0. 376) | |
| مشاهدات | 1500 |
| توجه داشته باشید: | * p |
| داده ها از داده های رأی در بسته Zelig گرفته شده است. |
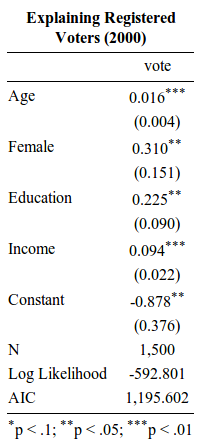
A regression table>
دانشجویی که برای اولین بار با یک جدول رگرسیون روبرو می شود ، سه چیز را مشاهده می کند.
- اعداد داخل پرانتز در کنار یک متغیر.
- اعداد در پرانتز در کنار یک متغیر نیستند.
- برخی از این اعداد که در پرانتز نیستند ، برخی از ستاره ها در کنار آنها هستند.
ضریب رگرسیون
ما اکنون با این مورد بحث خواهیم کرد ، با شروع مورد دوم. شماره ای که در پرانتز مشاهده نمی کنید ، ضریب رگرسیون نامیده می شود. ضریب رگرسیون تغییر مورد انتظار در متغیر وابسته (در اینجا: رأی) را برای افزایش یک واحدی در متغیر مستقل فراهم می کند.
من دانش آموزان تازه وارد رگرسیون را تشویق می کنم تا دو عنصر ضریب رگرسیون را مشاهده کنند. یعنی آیا مثبت است یا منفی؟ضریب مثبت نشانگر رابطه مثبت است. با افزایش متغیر مستقل ، متغیر وابسته افزایش می یابد. همچنین با کاهش متغیر مستقل ، متغیر وابسته کاهش می یابد.
ضریب منفی نشان دهنده یک رابطه منفی است. با افزایش متغیر مستقل ، متغیر وابسته کاهش می یابد. یک رابطه منفی همچنین نشان می دهد که با کاهش متغیر مستقل ، متغیر وابسته افزایش می یابد.
خطای استاندارد
تعداد پرانتز خطای استاندارد نامیده می شود. برای هر متغیر مستقل ، انتظار داریم در پیش بینی های خود اشتباه کنیم. این بصری است که پاسخ دهندگان مسن به احتمال زیاد رأی دهندگان ثبت نام شده اند ، که زنان به احتمال زیاد رأی دهندگان ثبت نام می کنند و افراد تحصیل کرده تر و ثروتمندتر احتمالاً رای دهنده ثبت نام می کنند. با این حال ، پیش بینی ها به ندرت 100 ٪ هستند. بسیاری از زنان رای نمی دهند. بسیاری از افراد تحصیل کرده تصمیم به ثبت نام به عنوان رأی دهندگان ندارند. خطای استاندارد برآورد ما از انحراف استاندارد از ضریب است.
با این حال ، خطای استاندارد به خودی خود مقدار مورد علاقه نیست. این به رابطه با ضریب رگرسیون بستگی دارد. این ما را به سومین مورد مورد علاقه سوق می دهد.
ستاره ها
ستاره ها در یک جدول رگرسیون با یک افسانه در پایین جدول مطابقت دارند. در مورد ما ، یک ستاره به معنی "p است<.1”. Two asterisks mean “ p <.05”; and three asterisks mean “ p <.01”. What do these mean?
ستاره ها در یک جدول رگرسیون میزان اهمیت آماری یک ضریب رگرسیون را نشان می دهد. منطق در اینجا از اصل نمونه گیری تصادفی ساخته شده است. اگر واقعاً هیچ تفاوتی بین (به عنوان مثال) زن و مرد در انتخاب رای دهندگان خود وجود ندارد ، پس چقدر احتمال دارد که "قرعه کشی" را بدست آوریم که چنین تغییری را پیشنهاد می کنیم؟
مقادیر P با تقسیم ضریب رگرسیون بر روی خطای استاندارد تعیین می شود تا یک آمار T (یا Z) بدست آید. این آمار همزمان با یک مقدار p است که برای تعیین اهمیت آماری استفاده می شود و قاعده شست در حوزه ما ، مقدار P تحت 0. 05 نشانگر "اهمیت آماری" است. با این حال ، این موارد میانی اطلاعات بیشتری برای یک دانشجوی کارشناسی ارشد در تلاش برای ارزیابی جدول رگرسیون دارند. بنابراین ، من فکر می کنم "Stargazing" (یعنی به دنبال ستاره ها) به عنوان دانشجویان قابل قبول است. فقط به دنبال "ستاره ها" باشید.
در مورد ما ، نتیجه می گیریم که سن ، جنس ، تحصیلات و درآمد به طور مستقل همه با احتمال اینکه یک رای دهنده ثبت نام شده باشد ، رابطه "آماری معنی دار" دارند. علاوه بر این ، همه با احتمال رأی گیری که بعید است صفر باشد ، رابطه مثبتی دارند.
مرحله سوم: درک آنچه جدول رگرسیون نمی گوید
این بخش با برخی احتیاط ها و هشدارها در مورد تفسیر خروجی رگرسیون مبتنی بر خطاهای رایج که دانش آموزان در سالهای تدریس من انجام داده اند ، نتیجه می گیرد.
به توزیع متغیر وابسته توجه کنید
ضرایب رگرسیون در رگرسیون خطی برای دانشجویان جدید در موضوع آسان تر است. در رگرسیون خطی ، ضریب رگرسیون تغییر مورد انتظار در مقدار متغیر وابسته را برای افزایش یک واحد در متغیر مستقل برقرار می کند. رگرسیون خطی به داشتن داده های سطح بازه ای به طور عادی توزیع می شود. دانشجویان با استفاده از داده هایی مانند تجارت ، درآمد ملی و غیره ، بیشتر در تحقیقات اقتصاد سیاسی رگرسیون خطی را مشاهده می کنند.
در یک رگرسیون لجستیک که من در اینجا استفاده می کنم - که معتقدم در تحقیقات بین المللی درگیری رایج تر است - متغیر وابسته فقط 0 یا 1 است و یک تفسیر مشابه گمراه کننده خواهد بود. به طور دقیق تر ، ضریب رگرسیون در رگرسیون لجستیک ، تغییر در شانس ورود به سیستم طبیعی (یعنی ورود به سیستم) از متغیر وابسته را به عنوان 1 ارتباط می دهد. و 1. اساساً ، ضریب رگرسیون را می توان به عنوان یک نسبت شانس برای به دست آوردن یک احتمال در نظر گرفت.
به توزیع متغیر مستقل توجه کنید
به عبارت دیگر: از نظر آماری قابل توجه خود "قابل توجه" نیست. یکی از رایج ترین اشتباهاتی که من می بینم دانش آموزان با تفسیر نتایج رگرسیون اشتباه می کنند ، اشتباه "آماری قابل توجه" با "بزرگ" یا "بسیار مهم" است. آیا این R. A. قصد فیشر برای درگیری "آماری قابل توجه" با "اثر بزرگ" برای ترویج روش او ، نگرانی من در حال حاضر نیست. کافی است بگوییم ، "از نظر آماری قابل توجه" کلمه ای است که لیست اخیر اصطلاحاتی را که دانشمندان آرزو می کنند عموم مردم از سوء استفاده دست بکشند ، ساخته است.
"از نظر آماری قابل توجه" یکی از این عباراتی است که دانشمندان دوست دارند فرصتی برای عقب نشینی و تغییر نام داشته باشند."قابل توجه" اهمیت را نشان می دهد ؛اما آزمون اهمیت آماری ، که توسط آماری انگلیس R. A. تهیه شده است. فیشر ، اهمیت یا اندازه اثر را اندازه گیری نمی کند. فقط آیا ما می توانیم با استفاده از مشتاق ترین ابزارهای آماری خود ، از صفر آن را متمایز کنیم."از نظر آماری قابل توجه" یا "از نظر آماری قابل تشخیص" بسیار بهتر خواهد بود.
در یک یادداشت مرتبط ، تصور اینکه جنسیت بیشترین تأثیر را در توضیح اینکه چه کسی یک رای دهنده ثبت نام شده است ، گمراه کننده خواهد بود. زن ، متغیر مستقل برای جنسیت ، فقط می تواند 0 یا 1 باشد. این باعث افزایش اندازه ضریب رگرسیون می شود ، اما خطای استاندارد را نیز افزایش می دهد. در همین حال ، آموزش و پرورش دارای چهار دسته است و درآمد 12 ارزش مختلف دارد. همه چیز برابر است ، این اثر تغییر یک واحدی در ضریب رگرسیون را پایین می آورد.
هیچ یک از چهار متغیر مستقل در رگرسیون یک مقیاس مشترک به اشتراک می گذارند ، بنابراین مقایسه سریع اندازه ضریب رگرسیون به عنوان تعیین کننده اندازه اثر نادرست خواهد بود.
قبل از شبیه سازی پس از تخمین ، یک راه در اطراف این استاندارد سازی است ، به ویژه توسط دو انحراف استاندارد به جای یک. تقسیم بر دو انحراف استاندارد اجازه می دهد تا پیش بینی کننده های مداوم از نظر متغیرهای باینری تقریباً مشابه باشند. وقتی این کار را انجام می دهیم (با بسته بازو در R) ، تأثیر زن نسبت به سایر پیش بینی کننده ها به نظر نمی رسد.
توضیح رای دهندگان ثبت شده در سال 2000 (آرکانزاس ، کارولینای جنوبی)
| آیا مخاطب رای دهنده است؟ | ||
| ضرایب غیرمستقیم | ضرایب استاندارد | |
| (1) | (2) | |
| سن | 0. 016 *** | 0. 575 *** |
| (0. 004) | (0. 151) | |
| زن | 0. 310 ** | 0. 310 ** |
| (0. 151) | (0. 151) | |
| تحصیلات | 0. 225 ** | 0. 459 ** |
| (0. 090) | (0. 184) | |
| درآمد | 0. 094 *** | 0. 739 *** |
| (0. 022) | (0. 170) | |
| ثابت | -0. 878 ** | 1. 706 *** |
| (0. 376) | (0. 110) | |
| مشاهدات | 1500 | 1500 |
| توجه داشته باشید: | * p | |
| داده ها از داده های رأی در بسته Zelig گرفته شده است. | ||
خلاصه M2 (M2) تماس: GLM (فرمول = رأی~ z.age + female + z.education + z.income, family = binomial(link = "logit"), data = voteincome) Deviance Residuals: Min 1Q Median 3Q Max -2.4247 0.3936 0.4869 0.5913 1.0284 Coefficients: Estimate Std. Error z value Pr(>| z |) (رهگیری) 1. 7055 0. 1105 15. 437
رهگیری یک متغیر مستقل نیست
ثابت (یعنی y-intercept) یک متغیر مستقل نیست بلکه برآورد ما از متغیر وابسته است که همه پیش بینی کننده های مدل روی 0 تنظیم می شوند. در بیشتر موارد ، این یک مقدار مورد علاقه نیست. با این حال ، من هنوز هم آن را در مدل سازی جدی می گیرم.
برای مثال ما به آمار خلاصه در ابتدای پست نگاه کنید و به جدول اول رگرسیون نگاه کنید. رهگیری -. 877 است. در اصل ، برآورد ما از احتمال اینکه یک رای دهنده ثبت نام شده برای شخصی که صفر سال (!) مرد با آموزش 0 در مقیاس 1-4 و درآمد 0 در مقیاس 4-16 است ، 877 است. در شانس ورود به رای دهنده. این آشکارا احمقانه است. همچنین در این شرایط به احتمال پیش بینی شده از . 293 دور می شود. با توجه به داده های ما ، این غیر منطقی است. با این حال ، اگر از آن سؤال کنید ، رایانه هنوز هم در یک رهگیری غیر منطقی قرار خواهد گرفت.
استاندارد سازی (یا کمترین مرکز) یک روش مفید برای دریافت رهگیری های معنی دار است. در خروجی رگرسیون خام که فقط با استفاده از متغیرهای استاندارد نشان داده شده است ، مرد با سن متوسط ، درآمد و تحصیلات دارای احتمال پیش بینی شده از 845 نفر از رای دهنده ثبت شده است (رهگیری: 1. 7055). با توجه به آمار خلاصه ما ، این یک رهگیری بسیار منطقی تر است.
ستاره های بیشتر به معنای "اهمیت" تر نیستند
سطوح بیشتر از اهمیت آماری برآوردهای دقیق تری را نشان می دهد ، اما خودشان نشان نمی دهند که یک متغیر مستقل "مهمتر" یا "بیشتر" از متغیر مستقل دیگر است که از نظر آماری نیز از صفر قابل تشخیص است.
نتیجه گیری
دانش آموزان جدید در جداول رگرسیون خواندن ، به منظور درک اطلاعات ارائه شده به آنها ، موارد زیر را انجام می دهند.
- بخش طراحی تحقیق را بخوانید تا این حس را داشته باشید که متغیرها چیست ، چگونه آنها را کدگذاری می کنند ، نویسنده در تلاش است تا توضیح دهد ، و چه پیش بینی کننده (ها) نویسنده معتقد است که آن را توضیح می دهد.
- به ضریب رگرسیون نگاه کنید و مشخص کنید که آیا مثبت است یا منفی. ضریب مثبت نشانگر رابطه مثبت است و ضریب منفی نشانگر رابطه منفی است.
- ضریب رگرسیون را بر روی خطای استاندارد تقسیم کنید (یعنی تعداد پرانتز). اگر مقدار مطلق آن بخش "حدود دو" باشد (از نظر فنی: 1. 96) ، نتیجه می گیریم که این اثر از نظر آماری "معنی دار" و از صفر قابل تشخیص است. این روابط مهم معمولاً در ستاره ها مشخص می شود.
من همچنین یک راهنمای مبتدی برای استفاده از R دارم اگر خواننده علاقه مند به آن باشد که من در مورد آن مجموعه داده نیز بحث می کنم.↩
گفته می شود ، هنوز هم سردرگمی قابل توجهی در بین دانشمندان علوم اجتماعی وجود دارد که در چارچوب مکرر که از آن می آید ، فاصله اطمینان وجود دارد. این پاراگراف همچنین با دقت در مورد ارتباط با ارزشهای P به منظور انتقال یک نکته اساسی تر به مخاطبان گسترده تر فراتر از کسانی که علاقه مند به موضوعات پیشرفته تر در روش آماری هستند ، آزادی می یابد. قطعاً کلاسهایی وجود دارد که به دانش آموز اجازه می دهد تا در این علفهای هرز حفر شود.↩
می توانید تبلیغات زیر را با Adblock Plus برای مرورگر خود غیرفعال کنید. Disqus برای نظرات/بازخورد عالی است اما من هیچ ایده ای نداشتم که با این تبلیغات گودال همراه باشد.
- استیون V. میلر
- عاملی
مؤسسه För Ekonomisk Historia Och Inteationella Alienter Universitetsvägen 10a ، 114 18 استکهلم ، سوئد
استراتژی برای تجارت گزینه های...
ما را در سایت استراتژی برای تجارت گزینه های دنبال می کنید
برچسب :
نویسنده : فریبا کامران
بازدید : 29
